Plan. Build. Run!
Your IT future with our HCI solution
Scalable. Cost-efficient. Hyperconvergent.
The Hybrid Core Concierge
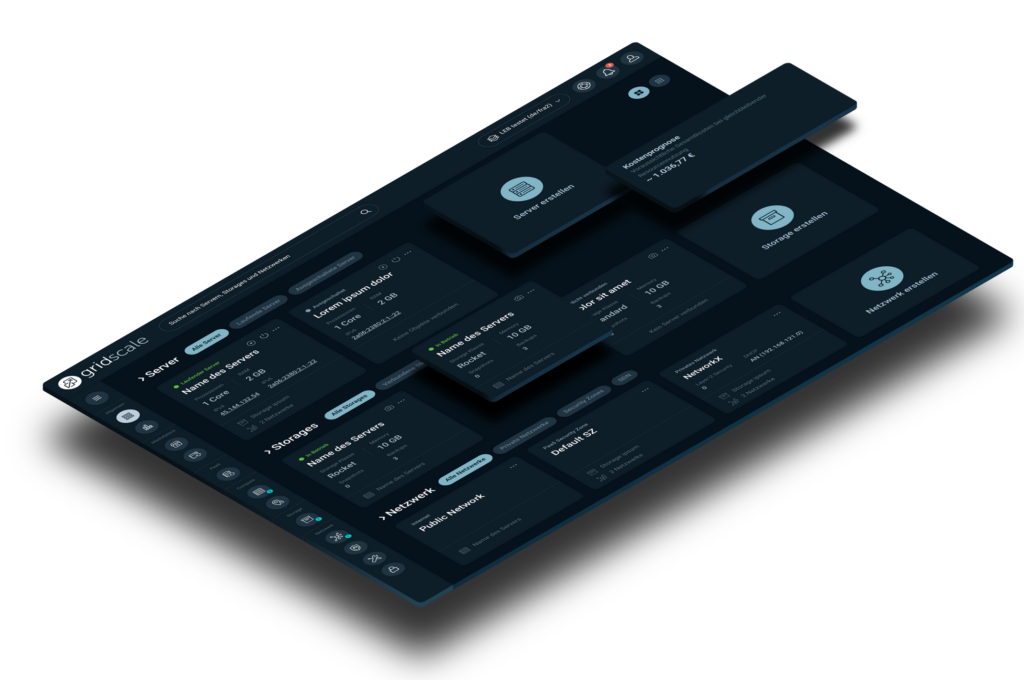
The world’s most user-friendly modular platform for building public, private or hybrid clouds.
Cloud technology without compromise
Compute
Effortless provisioning and scalability of VMs for any workload.
PaaS
Kubernetes, databases and more – as fully managed platform services.
GPU
Easy deployment of powerful AMD GPUs for your AI/ML applications, without complicated setup processes.
Data center
Cloud exit without loss of features: our hardware at your desired location. The fair alternative for your data center. ” Concierge
Leading companies rely on gridscale.
Strictest data protection
BSI:C5-certified: With our German headquarters and data center operations, we are subject to the strictest security and data protection requirements in the world.
Pay-as-you-grow
Our transparent cost model provides a precise overview of costs incurred at all times, broken down into accounts and/or customers.
Managed Services
A variety of managed services take over the operation of complex infrastructure. Automated workflows, monitoring and maintenance ensure a stable, high-performance environment.
Intuitive UX
Our panel is designed to get you to your destination as quickly and easily as possible. For geeks & nerds, there is of course also a powerful RESTful API.
Explain a powerful cloud platform in just three minutes? Only we can do that.

We can operate with the concentrated power of a hyperscaler, but do not need to worry about managing the services. This offers our customers maximum flexibility and significantly reduces our workload.
Dr. Fiete Dubberke
Co-Founder

Thanks to unlimited scalability, gridscale guarantees our customers a consistently positive user experience and data processing in accordance with strict German data protection regulations.
Christoph Geiser
Director Software Development

The new offering has enabled us to expand our existing software business very successfully. A growing number of clients are already using our contract management solution from the public cloud.
Dr. Frank Hofmann
Executive Board

I had two criteria when choosing a cloud provider. The environment had to be easy to set up and at the same time very user-friendly. gridscale really impressed us here.
Thorsten Kuligga
CEO

gridscale is ahead in terms of technology, communication and costs. And if we ever get stuck, we always get help quickly and reliably.
Manuel Kälin
CTO

gridscale’s IT infrastructures are located in Germany and are therefore subject to the strict local data protection guidelines. This was a decisive argument in favor of gridscale for this project.
Timo Springmann
CEO

Full transparency and maximum data sovereignty when choosing a location: from A for Amsterdam to Z for LuZern.







Latest blog posts

How companies secure their data sovereignty
Cloud made in Europe: How companies secure their data sovereignty “Germany is not digitally sovereign….

The future of enterprise software: AI agents are coming
The future of business software: The AI agents are coming! A new wave of development…

Rethinkinging corporate IT – with a hyperconverged infrastructure
Hyperconverged infrastructure (HCI) Rethinking corporate IT – with a hyperconverged infrastructure Manage an IT infrastructure…

Data sovereignty, innovation, security: why German companies are turning to edge computing
Data sovereignty, innovation, security: Why German companies rely on edge computing What is driving investment…