Kubernetes – All about Clusters, Pods and Kubelets

Due to the increasing complexity of IT infrastructures, monolithic software solutions seem to be less and less suitable to represent modern systems. Monolithic solutions are often too complex and inflexible. Meanwhile there are much better methods and applications of this concept.
The so-called microservices are basically nothing more than monolithic structures that are broken down into small parts in order to be able to scale and manage each individual application. The use of microservices, e.g. in the cloud, is one of the most important core elements today when using a complementary solution.
However, managing many individual microservices can in turn be very time consuming and costly. Why this is so becomes clear when you look at more complex IT structures: Often many applications are started, managed and restructured in parallel, sometimes several times a day. This effort can hardly be managed manually and must therefore be organized sensibly. The keyword of the hour here is orchestration using Kubernetes.
Kubernetes takes care of the complete provision of applications. The various applications are placed within servers, taking into account an optimal workload. Kubernetes communicates between the applications and tells them how to find each other. This in turn means that the administration work is significantly reduced.
The structure of Kubernetes
As already mentioned, Kubernetes takes the control of applications into its own hands. In order to understand this mechanism better, we need to take a closer look at the structure.
Kubernetes consists of two different levels: Master node and slave node. The Kubernetes master, also called control level, takes care of the administration and control of the whole system. The working node, on the other hand, only executes the provided applications. Each level consists of defined areas that must be known to understand how Kubernetes is able to orchestrate the applications.
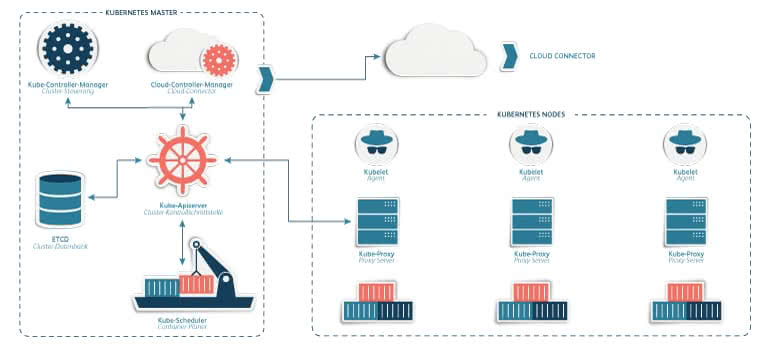
Control level
- The API server: performs communication and operations on the Kubernetes cluster
- The scheduler: schedules the applications (assigning a working node to each available component of the application)
- The Controller Manager: performs cluster-wide functions such as component replication, tracking of working nodes, handling node failures
- The distributed data storage etc: Here is the entire Clusterkonfiguration permanently stored
Work node
- Container runtime: executes the containers like DOCKER or rkt
- The Kubelet: communicates with the master and controls the containers on the node
- The Kubernetes service proxy (Kube proxy): performs proxy and load balancing functions for data traffic between application component
Before we describe the cooperation of the components in more detail, we will deal with the foundation stone of Kubernetes, the so-called Pods.
A Pod is a unit consisting of one or more containers that are always executed together on a node. This ensures that containers that would not work without each other are executed as one unit on the same node.
In addition, the containers of a Pod share a network namespace and thus talk to each other directly via loopback interface. However, pods communicate with each other via their IP address. The Pods are comparable to a host or a VM. When separating pods, the main concern is to scale and update the individual components independently of each other.
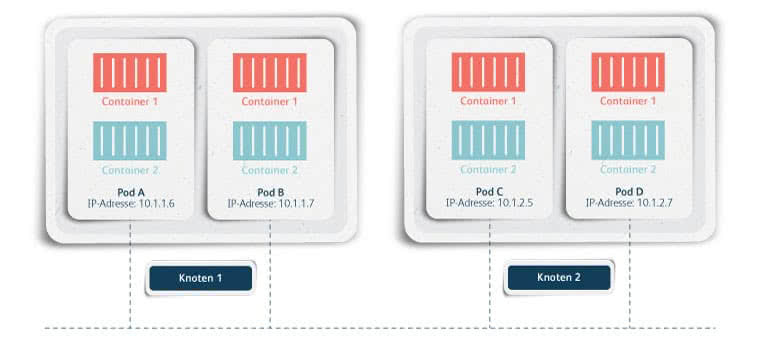
Communication of components
The control components described above communicate with each other indirectly via the API server, whereby the API server is the only one that communicates with etcd. The Kubernetes API server communicates directly with etcd; all other components read and write to etcd via the API server.
This has several advantages, such as a stable and optimistic locking system and, most importantly, a more stable validation. Furthermore, etcd is hidden from all components, which makes replacement easier.
The control level components must run via API servers, as this is the only way to ensure that the cluster status is updated consistently. The cluster status is queried and processed by the CRUD interface (Create, Read, Update, Delete), which is provided via REST API.
The API server ensures on the one hand that the written file in memory is always valid and on the other hand that changes can only be made by authorized clients.
The scheduler uses exactly this observation mechanism of API servers and waits for new pods to be assigned to new nodes as soon as they are created. Furthermore, the Scheduler processes the pod definition (the pod definition contains status, metadata and the description of the pod content) via the API server.
The task of the scheduler is to find a suitable node. To do this, it filters the node list to find a list of acceptable nodes by priority and selection of the most suitable node(s) for the pod. The scheduler thereby tries to achieve an even load on the nodes.
What is still missing is some control over the whole system. The controllers in the controller manager are responsible for this. The controllers have the task to adjust the actual state of the system to the target state. The target state is defined in the resources provided by the API server.
There are various controllers that are defined within controller manager processes, such as replication manager for a replication control, deployment controller, stateful set controller, and so on. These controllers communicate with each other indirectly using API servers. They monitor the API server so that they do not miss the change in resources.
They perform required operations (create a new object or change or delete an existing one) and then enter the new status in the resources.
After we have dealt with the control components, we will now look at two important components of the working nodes.
First we will introduce the orchestrated part, the scheduler. It schedules the specified container group to the available work nodes, based on the resource requirements of the container groups.
The kubelet allocates container runtime to download the required container images and execute them. The kubelet is the component that is responsible for all running processes in the work node. The kubelet registers the node on which it is executed. To do this, it creates a node resource in the API server. The kubelet then needs to keep track of the API server through pods to launch containers.
To do this, it instructs the container runtime environment such as Docker to execute a container based on a container image. The kubelet monitors the running containers and reports the status or resource usage to the API server. The developer leaves a description on the Kubernetes API server.
The original description of the Pod and other components comes from the developer of the application. It contains information about which container images contain the application and how the different components are related to each other or which applications should be executed by the same node. The description can also state which components a service provides for internal or external clients.
The service proxies, also called kube proxies, provide a connection between the clients and the services (defined via Kubernetes API). They ensure that the IP address and port of the service ends up at a Pod that also supports the same service. If there are multiple pods available for a service, the proxy performs load balancing simultaneously.
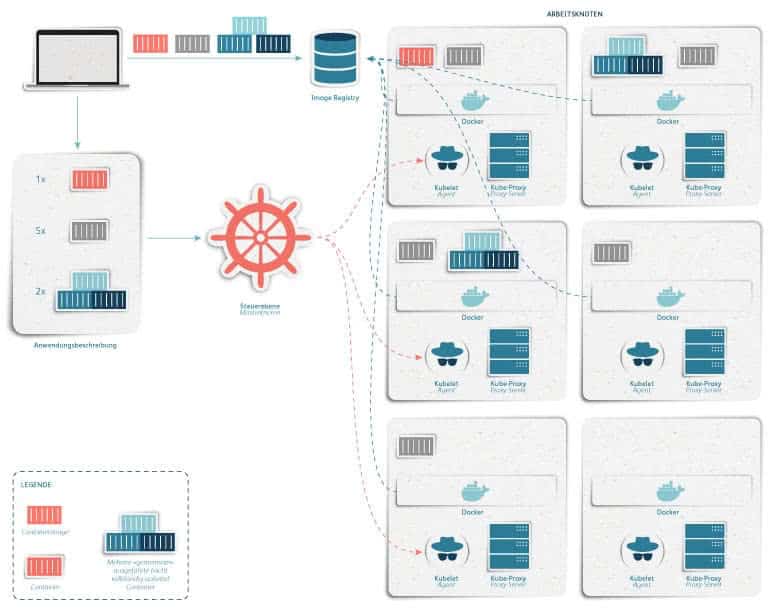
Advantages of Kubernetes
Kubernetes uses containers to prepare environments that the various applications require. K8s thus not only takes care of the administration work, but also simplifies the provision of services. In addition, developers no longer have to worry about which server runs which application as long as the server provides the required resources.
By describing the resource requirements of the developer, Kubernetes takes care only on which working nodes the applications should run. So he can clean up the applications and place them somewhere else if necessary. Thus Kubernetes can find optimal combinations much better than human developers and guarantee a good workload.
Another advantage is the status check of the working nodes. The larger the infrastructure, the more likely it is that one or the other node will fail. Here Kubernetes helps by moving applications to other nodes in case the original ones fail.
The automatic scalability of pods is another advantage. Since Kubernetes is able to scale a Pod vertically, unnecessary redundancies can be avoided.